Memory Leak Whack-a-Mole
October 27, 2016
[devops puma heroku sidekiq redis rails 
https://www.flickr.com/photos/tpapi/2765541278Memory leaks happen. They shouldn’t, but you just can’t squash enough of them. Or the leak is so slow that it takes hours to manifest. The trouble with memory leaks is that they are permanent for the life of a process. Once a process has expanded its VSZ, there’s no way in Unix to shrink it. So your process starts to bloat, eventually your servers page and thrash. Performance tanks. Then your pager starts going off and there goes your beauty sleep.
On your own servers this is when init or monit or god come into play; they watch your production processes for signs of trouble and then issue restarts. On Heroku and other PaaS, you don’t have access to these tools, in fact, quite often, you simply can’t restart a process; the container is the process. So what can you do? Killing the container might disrupt a critical transaction and piss off a user. Are you running a bunch of background tasks in Sidekiq? What happens if you pull the plug on a 100-thread worker?
The general recipe that won’t impact performance nor threaten data loss is as follows:
1. Detect the problem (trickier than you think);
2. Receive a webhook;
3. SignalNot to confuse you, but I’m not talking about Unix signals. I just mean “Send a message from one running process to another over some channel.” signal(7) might be used as the channel, but that’s an implementation detail. the process to stop accepting new work;
4. Wait for the process to finish all “in-flight” work and go “quiet,” and finally;
5. Signal the process to exit, allowing your cloud infrastructure to create a new container instance with a fresh memory footprint.
The challenges are that you might not be able to monitor within the same container, or that logs are streaming to an outside consumer. In addition, each application has different designs for signal handling.
Detection
Heroku will insert log messages into your application’s log stream, Error R14 for example, which signals that your container is over it’s memory quota.

You need to have a service that consumes the log stream, looks for patterns (regular expressions) and then triggers an action. Logentries.com has such a facility, but others do, too. It is best to experiment with a few of them before making a commitment.

Receiving the Webhook
One of Logentries features is the ability to send a webhook when a regular expression matches. Let’s create a controller that will accept the webhook message.The message format is vendor-specific, but it should be well documented.
LogentriesAuth is a special helper class to confirm that the message is authentic. We wouldn’t want some nefarious third party injecting messages into our system and restarting our servers over and over again, would we? A gist of it is available here, under the MIT license. https://gist.github.com/kmayer/f7e5a…
class LogentriesAlertsController < ApplicationController
skip_before_action :verify_authenticity_token
def create
return head(:unprocessable_entity) unless
LogentriesAuth.new(request).authorized?
# do something here...
head :ok
end
end
Once we’ve parsed the message and determined that we can act on it, we need to send a message, in this first case, to Puma. We’ll leverage a well known and commonly used service, Redis, as a general delivery post office; we’ll write a key/value pair and Puma will check for the key puma::stop::#{hostname} (where hostname looks like “web.5”). If the key is present, it will start the orderly shutdown process.
For brevity, I’ve omitted the private helper methods used in the controller. A complete gist is available here: https://gist.github.com/kmayer/abed3…
...
def create
return head(:unprocessable_entity) unless
LogentriesAuth.new(request).authorized?
if what =~ /R1[45]/ &&
who =~ /web\.\d+/
Redis.current.set(
"puma::stop::#{who}",
"*** HEROKU ERROR #{what} ***",
ex: 60.seconds
)
end
head :ok
end
private
...
Signal the application to stop accepting new work
Puma version 3 has a new feature that allows you to add custom plugins. With it, you can use Puma’s API to signal itself to stop; it will handle the rest of the clean up on its own. This custom plugin checks Redis for the “message” set by our controller. Puma background threads are lightweight enough that they won’t impact performance.
require 'puma/plugin'
require 'redis'
Puma::Plugin.create do
def start(launcher)
# Heroku sets this environment variable
hostname = ENV['DYNO']
return unless hostname
redis = Redis.current
# we can haz Redis?
return unless redis.ping == 'PONG'
signal_token = "puma::stop::#{hostname}"
in_background do
loop do
sleep 5
if (message = redis.get(signal_token))
redis.del(signal_token)
launcher.stop
break
end
end
end
end
end
Okay, all of the pieces are in place so we can do some integration tests. Let’s inject a log entry that looks close enough to match our regular expressions to trigger the alert.
Rails.logger.error 'heroku web.1 - - Error R14 (Memory quota exceeded)'
If all goes well, you should see the message hit your log, then sometime later, a POST on the LogentriesAlertsController, then a key/value pair inserted into Redis and finally, your Puma instance quitting. Your PaaS will spawn a new replacement with a clean, fresh serving of memory.
Wait for the process to finish all “in-flight” work
Sidekiq is a little trickier; It has an API for going quiet, which will complete all in-flight work, and won’t pull any new jobs off the queue; it has #stop! which will signal the main process to exit. But there’s no API call that says, “go quiet, then quit.” That’s okay, it’s easy enough to build a little class to wrap the Sidekiq process control API:
class SidekiqControl
def initialize(pattern)
@pattern = pattern
end
def quiet(timeout = 300)
begin
processes.each(&:quiet!)
sleep 1
timeout -= 1
busy = processes
.map { |p| p['busy'] }
.sum
end until busy == 0 || timeout < 0
end
def stop(timeout = 300)
quiet(timeout)
begin
processes.each(&:stop!)
sleep 1
timeout -= 1
end until processes.empty? || timeout < 0
end
private
def processes
::Sidekiq::ProcessSet.new
.select { |ps| @pattern === ps['hostname'] }
end
end
Signal the Process to Exit
Also, unlike Puma, there isn’t a similar plugin architecture for running arbitrary background threads. So we’ll build a little rake task:
task 'sidekiq:stop', [:pattern] => 'environment' do |_task, args|
sq_ctl = SidekiqControl.new(args[:pattern])
sq_ctl.stop
end
and now, let’s modify the controller:
class LogentriesAlertsController < ApplicationController
def create
...
if what =~ /R1[45]/ &&
who =~ /sidekiq\.\d+/
system "bundle exec rake sidekiq:stop[#{who}] &"
end
...
end
end
Again, we can do a quick integration test by injecting another log entry.
Rails.logger.error 'heroku sidekiq.1 - - Error R14 (Memory quota exceeded)'
Ken, that’s a lot of work! Is it worth it?
Boy, howdy! I have a Sidekiq worker that handles a “critical” job queue, for, you know, critical jobs. Every now and then a user submits a job with a ginormous data set that just makes our Nokigiri parser bloat like that guy from “Big Trouble In Little China.” If it weren’t for my suite of tools, the worker exceeds it’s memory allocation and grinds to a slow crawl. Instead, we signal the worker, spawn a new one, and work goes on it’s merry way.
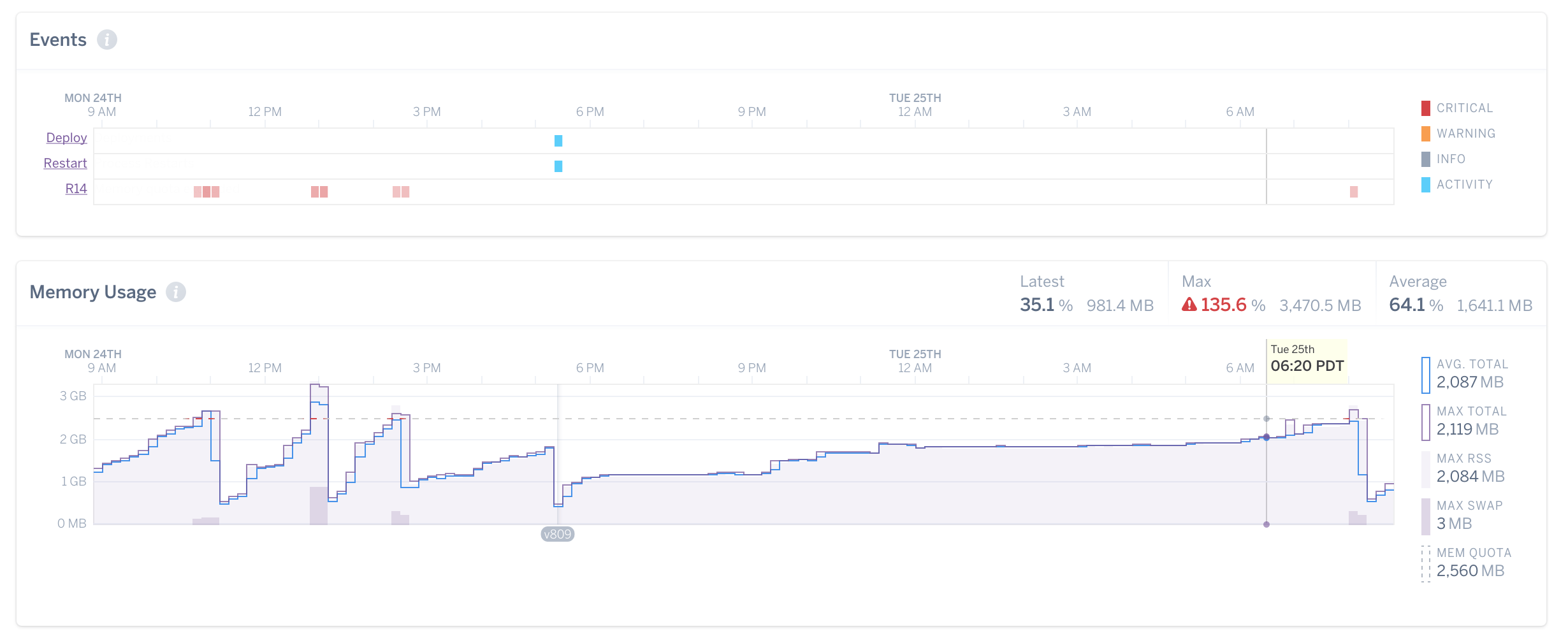
This keeps my application running and my users happy. I can also allocate the technical debt-service at a time of my choosing, instead of being forced to react to a crisis. Is it perfect? Hell, no, but my pager rings less.
Oh, yeah, and remember: